hashCode()와 equals()
hashCode와 equals를 알아보고 override 해야 하는 이유에 대해 알아보자

Object 제공 method
Object 클래스란?
Object 주요 method
hashCode()
hashCode가 제공하는 전략은 어떤게 있을까?
hashCode 전략
hashCode 기본 전략은 어떻게 될까?
equals()
equals()의 기본 전략은 어떻게 될까?
동등성 비교 로직은 어떻게 작성할까?
equals 구현 전략
hashCode() 왜 필요한가?
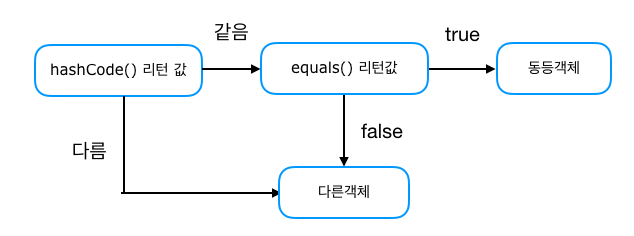
hashCode()가 같을 경우?
hashCode가 동일할 경우, 조회는 항상 O(n)의 효율을 가지는가?
내부 자료구조를 변경하는 기준은 어떻게 되나?
참고
Last updated